近日,我院吴泓辰团队在信息处理领域国际SCI一区顶级期刊 《Information Processing and Management》 上发表题为 “CLEAR: Prototype-conditioned flow purification for LLM-based rumor detection with Dirichlet evidential learning” 的研究论文。该研究针对社交媒体中谣言检测面临的语义模糊、评论噪声极化及虚假关联等难题,创新性地提出了 CLEAR(上下文潜在对齐捕获网络) 框架,显著提升了复杂场景下的谣言识别能力。
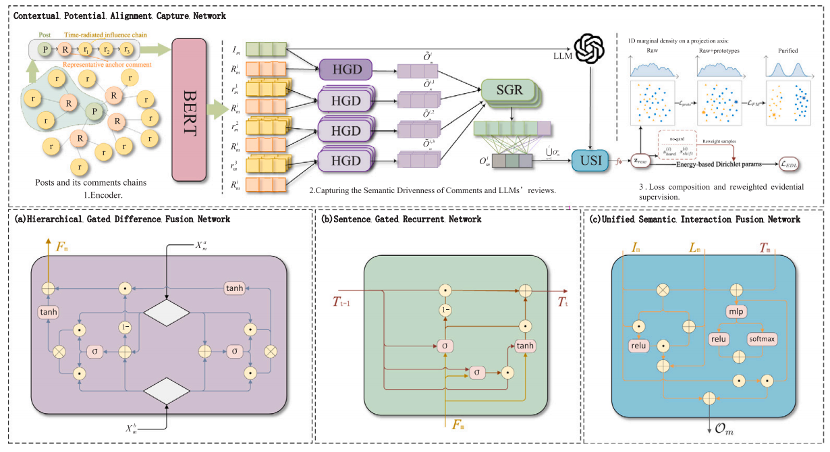
CLEAR 框架融合了两大核心技术:原型条件流纯化与狄利克雷证据学习。通过分层建模评论的动态演化规律,并结合大语言模型(LLM)辅助的真实性评估,框架实现了具备可信度感知的预测。研究还设计了熵自适应硬偏移重加权策略,有效抑制了噪声数据导致的模型“捷径学习”问题,增强了模型的鲁棒性。
大量实验验证了 CLEAR 的优越性能。在公开的 Weibo-19(2927条样本)和 PHEME(2018条样本)数据集上,CLEAR 的检测准确率分别达到 93.16% 和 91.56%,比近年主流优秀基线模型平均高出 3.2 和 5.5 个百分点。为严格测试模型在分布偏移场景下的泛化能力,团队自建了 VRDD 数据集(含4020条社交媒体帖子,其中谣言1672条)。该数据集决策边界密集,重点收录语义模糊的疑难样本。实验结果表明,CLEAR 能够适配不断演变的谣言模式,展现出优异的鲁棒性,同时验证了重加权策略存在课程训练依赖效应。该论文的第一作者为博士生房晓畅,共同作者包括张化祥教授等。研究受国家面上基金“面向深度伪造的多模态虚假信息检测技术”(项目号:62572288)资助。此次成果为社交媒体谣言检测提供了全新的证据驱动型解决方案,对净化网络环境、提升信息可信度具有重要意义。
图文:吴泓辰
编辑:徐扬
审核:



